

Este resultado ha sido parcialmente financiado por MCIN/ AEI/10.13039/501100011033/

Este resultado ha sido parcialmente financiado por FEDER/ Junta de Andalucía
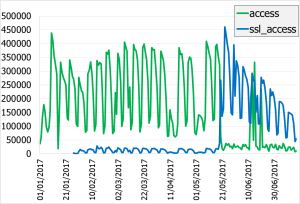
Se ha adquirido todo el tráfico a los servicios HTTP y HTTPS durante 6 meses a partir de los archivos de traza del servidor Apache. El tráfico capturado se organiza en archivos diarios por servicio etiquetados con el número de mes y día. Se han agrupado estos archivos por día y se ha añadido un identificador único a cada línea. Los datos más relevantes de la adquisición son:
| Bloque | Vol (GB) | # arch | # líneas | #Uris |
|---|---|---|---|---|
| access_log | 4.15 | 198 | 34 573 623 | 34 074 832 |
| ssl_access_log | 1.17 | 172 | 13 328 700 | 13 328 164 |
| apachelog (ambos) | 5.99 | 198 | 47 902 323 | 47 402 996 |
 |
 |
|
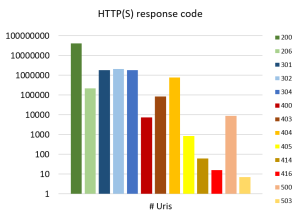
| Evolución temporal del número de peticiones capturadas por servicio | Distribución de peticiones por código de respuesta |
Se han categorizado los registros (Normal / TP / FP / etc.) siguiendo el método publicado en:
A methodology for conducting efficient sanitization of HTTP training datasets Artículo de revista
En: Future Generation Computer Systems, vol. 109, pp. 67–82, 2020, ISSN: 0167739X.
Por tanto, se han preprocesado y normalizado las URI, anonimizando la información sensible. Se ha procedido a la detección de ataques mediante SIDS a partir de la herramienta Inspectorlog desarrollada por nuestro grupo. Se han usado reglas Talos+ETOpen (M2), nemesida y CRS en configuración PL1 y PL2. Se han supervisado y marcado como TP o FP todas las detecciones. Finalmente, en la fase siguiente se ha analizado el vocabulario y añadido etiquetas para marcar ataques adicionales no detectados por los SIDS y registros que incumplen las normas de aplicación a los URI (fuera de especificación, OOS).
Dataset Biblio-US17
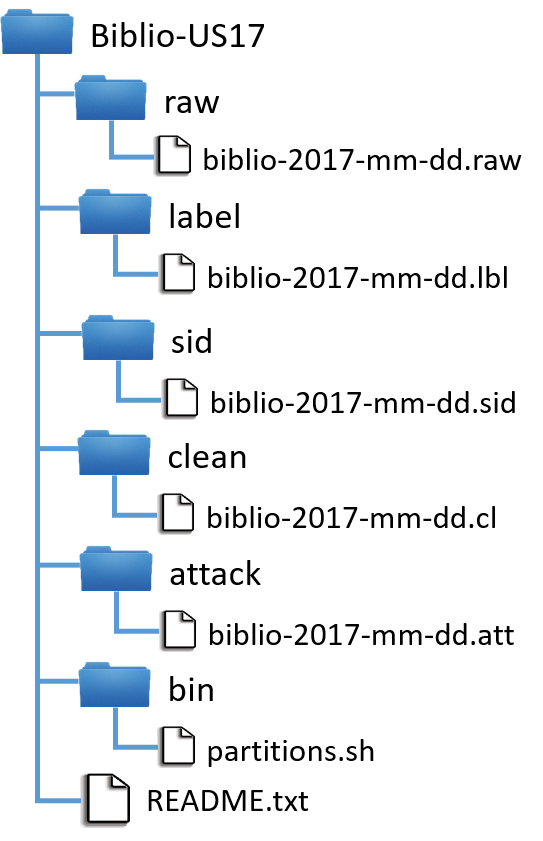
El dataset se organiza en una estructura en árbol (subdirectorios) cada uno conteniendo diferentes tipos de archivos o conjuntos. Se proporcionan 5 conjuntos de archivos y dos esquemas de particionado. Los archivos de las diferentes particiones deben ser generados a partir del dataset utilizando el script proporcionado. Los conjuntos de archivos (subdirectorios) incluidos son: – Archivos raw: Archivos de entrada. Contienen las peticiones consideradas válidas tras el preprocesado obtenidas directamente a partir de las capturas. Se encuentran anonimizadas. – Archivos labels: Contienen las etiquetas asignadas durante el análisis. – Archivos SID: Contienen información sobre las alertas generadas por los SIDS. – Archivos clean: Contienen las peticiones consideradas limpias tras la sanitización. Este es el dataset a utilizar como tráfico normal. – Archivos attack: Peticiones clasificadas como ataques (sólo LVL1 -indubitados-).
Los registros en cada conjunto se organizan en archivos por días denominados
siendo <mm> el número del mes, <dd> el día y <ext> una extensión relacionada con el tipo (y formato) de contenido: .raw para archivos RAW .lbl para archivos LABEL .cl para archivos CLEAN .sid para archivos SID .att para archivos ATTACK
|  |
Indexación
Las peticiones se identifican unívocamente mediante un código asignado a cada una de las entradas de los archivos de traza originales que permite su localización en los mismos. El formato del identificador es:
siendo MM-DD el número de mes y día del archivo original, F el tipo de tráfico (A: HTTTP, S: HTTPS) y nnnnnn el número de orden de la petición en el archivo de traza original.
Todos y cada uno de los registros de todos los archivos contienen el identificador de la petición original asociada.
Formatos de los archivos
Cada archivo contiene registros cada uno compuesto por un conjunto de campos delimitados por tabuladores. Cada registro corresponde a una línea y comienza siempre por un identificador. Los campos dependen del tipo de registro/archivo:
– Archivos RAW, CLEAN y ATTACK
Los archivos de tipo RAW y CLEAN contienen las peticiones incorporadas en el dataset. Cada línea corresponde a campos seleccionados extraídos de las trazas del servidor Apache precedidos de su identificador.
Cada registro consta de un conjunto de campos delimitados por tabuladores:
Ejemplo de registro:
[02-18-A001234] GET /2003/padron.html HTTP/1.1″ 200 11800
– Archivos LABEL
Cada línea contiene el conjunto de etiquetas asignadas al registro identificado en el primer campo. Los campos se encuentran delimitados por tabuladores. El formato y valores posibles se muestran en la tabla siguiente:
| Detección SIDS | Supervisión SIDS | Análisis segmentos | ||||||
| Registro | URI_ID | IL_M2 | IL_NEM | MS_PL1 | MS_PL2 | ManualTP | Phase2TP | OOS |
|---|---|---|---|---|---|---|---|---|
| Valores | [MM-DD-Fnnnnnn] | 0 – No detec. | 0 – No detec. | 0 – No detec. | 0 – No detec. | -1 – No etiquetado | -1 – No etiquetado | 0 – Normal |
| 1 – Detectado | 1 – Detectado | 1 – Detectado | 1 – Detectado | 0 – Falso Positivo | 1 – Ataque LVL1 | 1 – OOS RFC | ||
| 1 – Ataque LVL1 | 2 – Ataque LVL2 | 2 – OOS Cod | ||||||
| 2 – Ataque LVL2 | 3 – Ataque LVL3 | 3 – OOS Fmt | ||||||
| 4 – Ataque LVL4 | 4 – OOS Sem | |||||||
| Ejemplo | [02-18-A001234] | 0 | 1 | 0 | 1 | 0 | -1 | 2 |
-Un valor 1/0 en una etiqueta de detección SIDS indica que el detector correspondiente sí/no ha generado alertas.
-Un valor -1 en una etiqueta significa que no se ha asignado valor por no corresponderle o no haberse procesado ese campo (valor por defecto).
-Un valor 1-4 en las etiquetas ManualTP y Phase2TP implican que se ha etiquetado el URI como ataque del nivel correspondiente y, análogamente, un valor 1-4 en el campo OOS indica que el URI no es conforme y codifica el motivo.
| Ataques | OOS | |||
| ETIQ. | Expl. | ETIQ. | Expl. | |
|---|---|---|---|---|
| 1 | Indubitados | 1 | Incumplen RFC 3296 | |
| 2 | Dependientes del contexto / aplicación | 2 | Errores codificación caracteres extendidos/caracteres no permitidos | |
| 3 | Percent encoding | 3 | Uso de ‘//’ al inicio del URI | |
| 4 | DoS | 4 | Otros / errores semánticos | |
Los registros RAW que no activan ninguna etiqueta (valores por defecto, en azul en la tabla) no generan registro LABEL asociado. Por tanto, los registros RAW para los que no exista registro LABEL se entiende que toman los valores por defecto (en azul en la tabla).
Es importante indicar que, dado el procesamiento en fases, no se activan todas las etiquetas posibles para cada registro. Si un registro es etiquetado como ataque en ManualTP, no se realizan procesamientos posteriores sobre él. Por tanto, no se activará ninguna etiqueta de la fase de análisis de segmentos.
– Archivos SID
Cada línea contiene información sobre las alertas generadas por el registro identificado en el primer campo. Los campos se encuentran delimitados por tabuladores. El formato es:
siendo SID el identificador de la regla activada y DET el código del detector asociado, según:
| DET | Detector | Reglas | Observaciones |
|---|---|---|---|
| 1 | Snort | Talos+ETOpen – Marzo de 2022 | Sids 1024-899999 (Talos) y 2000000-2999999 (ETOpen) |
| 2 | Nemesida | Nemesida (públicas) – Nov. 2021 | Sids originales renumerados > 3000000 |
| 3 | ModSecurity | CRS3.3.2 (PL1) – Abril de 2022 | Sids 900000-999999 |
| 4 | ModSecurity | CRS3.3.2 (PL2) – Abril de 2022 | Sids 900000-999999 |
Particionado
Se proporcionan dos esquemas de particionado: TI (time independent, independiente en el tiempo) y TD (time dependent, dependiente en el tiempo). Para cada esquema, se establece una distribución de los registros en las proporciones 60/30/10 para entrenamiento/test/validación.
Para generar las particiones debe utilizarse el script partitions.sh suministrado en el directorio /bin.
La partición TI organiza los registros en archivos por día, mientras que la partición TD se organiza en 7 bloques numerados de 1 a 7.
Los detalles relativos a los esquemas de particionado y su finalidad y uso pueden consultarse en el artículo referenciado en la sección de documentos técnicos.